
Pengertian,Fungsi Serta Cara Kerja Dari Web Crawler
Apa Itu Web Crawler ?
Merupakan program komputer atau skrip otomatis yang bekerja melalui World Wide Web dengan cara yang telah ditentukan dan metodologi untuk mengumpulkan data.Tools web crawler mengumpulkan detail tentang setiap halaman : judul,gambar,kata kunci,halaman tertaut lain dan lain-lain.Web Crawler dikenal juga sebagai spider atau bot spider yakni program yang bekerja dengan cara seperti laba-laba merangkak dan bergerak dari satu situs web ke situs web lain,serta menangkap setiap situs web.Semua isi telah dibaca dan entri dibuat untuk indeks mesin pencari.
Fungsi Web Crawler
Ada beberapa fungsi dari web crawler :
- Membandingkan Harga
Bisa membandingkan harga dari suatu produk di internet,sehingga harga atau data dari produk tersebut bisa akurat.Jadi,saat kalian mencari suatu produk,harga produk tersebut akan langsung muncul tanpa perlu masuk ke website penjual.
- Data untuk Tools Analisis
Tools analisis website seperti Google Search Console dan Sceaming Frog SEO mengandalkan web crawler untuk mengumpulkan data-data dan melakukan indexing.Sehingga data yang dihasilkan akurat dan terbaru.
- Data Untuk Statistik
Web crawler memberikan data penting yang bisa digunakan untuk website berita atau website statistik.Misal,hasil pencarian berita yang akan muncul di Google News.Untuk muncul di Google News,website memerlukan sitemap khusus yang akan di-crawl oleh web crawler nantinya.
Contoh Web Crawler
Setiap mesin pencari di internet memiliki web crawlernya sendiri,jika kalian melakukan pencarian dengan keyword yang sama di mesin pencari lain akan menghasilkan hasil yang berbeda pula.
Beberapa web crawler lain selain Googlebot,sebagai berikut :
- DuckDuckBot dari DuckDuckGO.
- Bingbot dari Bing.
- Slurp Bot dari Yahoo.
- Baiduspider dari Baidu (mesin pencari dari China).
- Yandex Bot dari Yandex (mesin pencari dari Rusia).
- Sogou Spider dari Sogou (mesin pencari dari China).
- Exabot dari Exalead.
- Alexa Crawler dari Amazon.
Google sebagai penguasa pangsa pasar mesin pencari menampilkan hasil pencarian lebih baik dari mesin pencari lainnya.Karena itu,kalian harus memprioritaskan agar website diindeks oleh Googlebot.
Arti Web Crawler Untuk SEO
Web crawler menelusuri konten yang ada di internet dan menyimpan konten yang relevan pada database sebuah search engine.Melalui proses crawling dan indexing,search engine menentukan dan mengurutkan konten yang paling relevan dalam sebuah pencarian.Jika konten kalian mendapatkan peringkat atas di SERP (search engine result pages),tentu trafik organik kalian akan bertambah.Untuk itu penting memastikan bahwa halaman website kalian bisa melalui proses crawling dan indexing yang benar.
Jjika kalian tidak tahu cara memastikannya,kalian bisa menggunakan tips and trick cara agar cepat terindex Google seperti berikut :
Mendaftarkan website di Google Webmaster (Console)
Karena Google sekarang menjadi penyumbang traffic terbesar dari Internet,Untuk bisa cepat terindeks kalian harus segera mungkin mendaftarkan website di Webmaster agar dikenali Google.Tool ini bersifat gratis,tinggal mendaftar dengan menyiapkan email.
Berikut langkah-langkah mendaftar di Google Webmaster :
- Akses ke website Google Search Console.
- Login dengan akum email Google yang kalian miliki.
- Masuk ke dashboard Console, silahkan pilih Add property.
- Pilih URL Prefix,lalu masukan URL website dan klik Continue.
- Ada berbagai pilihan verifikasi yang bisa dipilih,tetapi paling mudah dengan upload file HTML script dengan ektensi .html ke server hosting atau memasukan HTML Tag tambahan pada template website setelah <head>.
- Lalu klik Verify dan tunggu sampai berhasil.
- Agar website terindex oleh Google, setiap posting artikel baru silahkan copy URL dan masukan di kolom submit pada bagian atas.
- Klik Enter dan pilih Request Indexing,tunggu proses selesai.
- Cek artikel sudah terindex atau belum silahkan buka Google Search,paste URL artikel tadi dikolom pencarian Google,jika sudah muncul berarti artikel sudah terindex Google.
Menambahkan Sitemap Website
Sitemap atau peta situs memiliki fungsi untuk memudahkan robot crawler spider Google untuk melakukan index pada website.Ada beberapa sitemap yang perlu kalian submit ke Search Console diantaranya author,category,post,page dan tag.
Berikut langkah-langkah membuat sitemap website :
- Login akun Search Console atau Webmaster.
- Jika sudah sampai pada dashboard Console, silahkan scroll ke bagian tengah dan pilih menu Sitemap.
- Masukan URL Sitemap pada website dan lakukan verifikasi hingga berhasil.Jika menggunakan plugin SEO WordPress seperti Yoast SEO,sitemap ini sudah ada tinggal submit URL ke halaman Console.
- Pastikan semua sudah disubmit dan statusnya sukses.
Setelah Terindex
Setelah artikel terindex di Google prosesnya sudah selesai.Namun ini hanya proses awalnya,setelah itu kalian harus melakukan optimasi website agar bisa bersaing dihalaman pertama pencarian Google dengan teknik SEO.Ada banyak metric yang harus diperhatikan mulai dari riset keyword,navigasi website,kualitas konten,internal link,external link dan kecepatan website.
Penggunaan Web Crawler
Pertama kali Google mulai menggunakan web crawler untuk mencari dan mengindeks konten sebagai cara termudah untuk menemukan situs web berdasarkan kata kunci dan frasa.Popularitas dan beragam aplikasi hasil pencarian terindeks akhirnya berkembang untuk dimonetisasi.Mesin pencari dan sistem TI membuat web crawler mereka sendiri yang diprogram dengan algoritma berbeda.Proses ini meliputi merangkak di web,memindai konten dan membuat salinan halaman yang dikunjungi untuk pengindeksan berikutnya.Hasilnya terlihat,karena sekarang kalian dapat menemukan informasi atau data apa pun yang ada di web.
Dapat menggunakan crawler untuk mengumpulkan jenis informasi tertentu dari halaman web,seperti :
- Ulasan terindeks dari aplikasi agregator makanan.
- Informasi untuk penelitian akademik.
- Riset pasar untuk menemukan tren paling populer.
- Layanan atau lokasi terbaik untuk penggunaan Pribadi.
- Pekerjaan atau peluang dalam bisnis.
Penggunaan web crawler di bidang kecerdasan bisnis meliputi :
- Mendeteksi situs web berbahaya.
- Melakukan peningkatan popularitas pemimpin atau bintang film.
- Melacak perubahan dalam konten.
- Mendeteksi situs web berbahaya.
- Pengambilan harga otomatis dari situs web pesaing untuk strategi penetapan harga.
- Mengidentifikasi calon buku terlaris untuk platform e-commerce dengan mengakses data dari kompetisi.
- Mengakses umpan data dari ribuan merek serupa.
- Mengindeks tautan yang sering dibagikan di jejaring sosial.
- Akses dan indeks daftar pekerjaan berdasarkan ulasan dan gaji karyawan.
- Benchmarking harga berbasis kode pos dan katalog untuk pengecer.
- Membangun database tinjauan layanan dengan menggabungkan ulasan yang tersebar di beberapa sumber.
- Mengekstrak data dari kantor berita dan umpan sosial untuk berita terkini,digunakan untuk menghasilkan konten otomatis.
- Mengakses data pasar dan sosial untuk membangun mesin rekomendasi keuangan.
- Menemukan ruang obrolan terkait teroris.
Cara Kerja Web Crawler
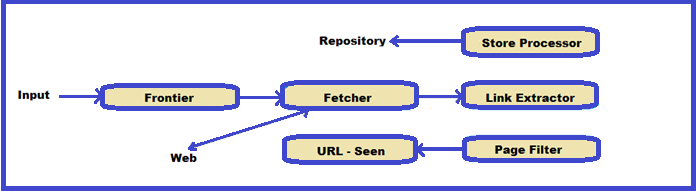
Berjalan melalui web untuk menemukan halaman situs web untuk dikunjungi,menggunakan beberapa algoritma untuk menilai konten atau kualitas tautan dalam indeksnya.Aturan ini menentukan perilaku pendataannya: situs mana yang akan di-crawl,seberapa sering meng-crawl ulang halaman,berapa banyak halaman di situs yang diindeks dan sebagainya.Ketika mengunjungi situs web baru,lalu mengunduh robot.txt yaitu protokol “standar pengecualian robot” yang dirancang untuk membatasi akses tak terbatas oleh tools web crawler.File berisi informasi peta situs (URL untuk di-crawl) dan aturan pencarian (halaman mana yang akan di-crawl dan bagian mana yang harus diabaikan).
Web Crawler melacak setiap link internal maupun eksternal,untuk ditambahkan ke halaman berikutnya yang dikunjungi. Proses ini diulang sampai crawler mendarat di halaman tanpa tautan lagi atau mengalami kesalahan seperti 404 dan 403 untuk memuat konten situs ke dalam database dan indeks mesin pencari.Ini merupakan database besar berisi kata dan frasa yang ditemukan di setiap halaman dan menentukan di mana kata-kata terjadi di halaman web berbeda.Saat fungsi pencarian dan kueri digunakan,itu membantu end user untuk menemukan halaman web dengan kata atau frasa yang dimasukkan.
Pengindeksan merupakan fungsi penting dari mesin pencari web crawler.Algoritma menafsirkan tautan dan nilainya dalam indeks untuk memberikan hasil pencarian yang relevan.Ketika mencari kata atau frasa tertentu,mesin pencari akan mempertimbangkan ratusan faktor untuk memilih dan menyajikan halaman web terindeks kepada kalian.
Contoh faktor yang dipertimbangkan adalah :
- Kualitas konten.
- Konten yang cocok dengan kueri user.
- Jumlah link yang menunjuk ke konten.
- Berapa kali dibagikan secara online.
Sebagian besar mesin pencari memiliki beberapa web crawler yang bekerja pada saat yang sama dari server berbeda.Proses dimulai dengan daftar alamat web dari crawl sebelumnya dan peta situs yang disediakan oleh pemilik situs web.Saat web crawler mengunjungi situs web,tautan yang ditemukan di situs tersebut digunakan untuk menemukan halaman lain.Administrator SEO situs web sering menggunakan backlink ke situs web kalian yakni sinyal untuk mesin pencari yang dijamin orang lain untuk konten kalian.
Sekian artikel kali ini semoga bisa bermanfaat untuk kalian semua 🙂