
Peran Penting Apache Cassandra dan Hadoop Di Dunia Big Data
Halo Sobat Teko! Sedang bingung memilih teknologi untuk big data? Di era digital saat ini, data telah menjadi “harta karun” baru bagi banyak perusahaan. Namun, semakin banyak data yang dikumpulkan, semakin rumit juga cara menyimpan, memproses, dan menganalisisnya. Mungkin Anda sudah mendengar atau bahkan merasa bingung antara dua nama besar ini, yakni Apache Cassandra dan Hadoop.
Keduanya sering kali dianggap sebagai solusi yang efektif untuk mengelola data dalam skala besar atau big data. Namun, apa yang membedakan Apache Cassandra dari Hadoop? Apakah fungsi keduanya sama? Kapan sebaiknya kamu menggunakan Cassandra, dan kapan lebih baik memilih Hadoop?
Mari kita bahas bersama-sama dengan cara yang santai tetapi tetap mendalam, sehingga Anda bisa membuat pilihan yang tepat sesuai dengan kebutuhan proyek atau perusahaanmu.
Mengenal Apache Cassandra dan Hadoop
Sebelum membahas perbandingan antara keduanya, mari kita ulas secara singkat. Dibuat untuk memenuhi kebutuhan data di era modern, Apache Cassandra mampu menangani jutaan data setiap detiknya secara merata di berbagai server tanpa mengorbankan kinerja. Sistem ini dirancang untuk dapat beroperasi di banyak server secara bersamaan tanpa adanya gangguan.
Sementara Hadoop merupakan kerangka kerja big data yang terkenal dengan dua komponennya, yaitu HDFS sebagai tempat penyimpanan data, dan MapReduce untuk pengolahan data dalam bentuk batch. Umumnya digunakan untuk analisis data besar secara bersamaan.
Jadi, meskipun baik Apache Cassandra maupun Hadoop memiliki tujuan yang sama dalam konteks big data, cara mereka melakukannya sangat berbeda.
Arsitektur Dasar Keduanya
Agar lebih memahami perbedaan keduanya, penting untuk melihat bagaimana masing-masing arsitektur berfungsi. Apache Cassandra mengadopsi struktur peer-to-peer, yang berarti semua node memiliki peran yang setara. Tidak ada node yang berfungsi sebagai pemimpin. Jadi, meskipun salah satu node mengalami gangguan, sistem tetap berjalan normal. Ini menjadikan Cassandra sangat robust dan dapat dengan mudah ditingkatkan ke sejumlah server tanpa kesulitan.
Di sisi lain, Hadoop menerapkan model master-slave. Di sini terdapat NameNode yang berperan sebagai “otak” utama yang mengatur semua penyimpanan dan distribusi file, sementara DataNode berfungsi sebagai tempat penyimpanan data. Model ini sangat cocok untuk pengolahan data dalam jumlah besar, tetapi ada risiko jika NameNode mengalami masalah, karena ia berfungsi sebagai pusat kontrol.
Dari aspek desain, jelas bahwa Apache Cassandra dan Hadoop memiliki pendekatan yang sangat berbeda. Cassandra unggul dalam penyebaran data dengan waktu aktif yang tinggi, sedangkan Hadoop lebih baik dalam pengolahan data dalam volume besar.
Cara Kerja Apache Cassandra dan Hadoop
Walaupun keduanya termasuk dalam kategori teknologi big data, Apache Cassandra dan Hadoop memiliki cara yang berbeda dalam mengelola data. Apache Cassandra menggunakan metode pemisahan dan penggandaan data. Data dibagi ke dalam beberapa node, kemudian direplikasi ke node lain untuk meningkatkan keamanan dan kecepatan akses. Ketika kamu melakukan penulisan atau pembacaan data, Cassandra akan langsung mengarahkan permintaan ke node yang tepat, tanpa menunggu instruksi dari satu server pusat.
Sementara itu, Hadoop lebih berfokus pada proses pemrosesan batch, di mana data diolah dalam blok-blok besar secara bertahap. Hadoop menyimpan data dalam potongan besar di HDFS, lalu memprosesnya menggunakan MapReduce, di mana data dibagi, dikerjakan oleh banyak node secara bersamaan, dan kemudian hasilnya digabungkan kembali. Ini sangat ideal untuk analisis yang besar dan tidak memerlukan data secara langsung.
Dengan demikian, dapat disimpulkan bahwa Apache Cassandra dan Hadoop memiliki pendekatan yang berbeda: Cassandra mengutamakan ketersediaan dan kecepatan akses data real-time, sedangkan Hadoop lebih unggul dalam pemrosesan data dalam skala besar yang terstruktur.
Kapan Harus Memilih Apache Cassandra dan Hadoop?
Sekarang, pertanyaan pentingnya adalah: kapan seharusnya menggunakan Apache Cassandra dan kapan lebih tepat menggunakan Hadoop?
Jika Anda memerlukan sistem yang dapat menangani data dalam waktu nyata, sering melakukan penyimpanan data dalam jumlah besar, dan menginginkan sistem yang tetap berjalan meskipun ada node yang mengalami kegagalan, Apache Cassandra adalah pilihan yang tepat. Contohnya termasuk aplikasi perpesanan, Internet of Things, atau dashboard analisis waktu nyata.
Di sisi lain, Hadoop lebih sesuai untuk analisis data dalam skala besar yang tidak harus dilakukan secara langsung. Misalnya, Anda sedang melakukan analisis log mingguan, memproses data historis yang banyak, atau menjalankan proyek data science yang tidak memerlukan data secara real-time.
Banyak perusahaan juga menggabungkan Apache Cassandra dan Hadoop. Cassandra sering digunakan untuk menyimpan dan mengakses data dengan cepat dan merata, sedangkan Hadoop berfungsi untuk memproses analisis data dalam jangka waktu yang lebih lama. Kombinasi ini dapat menjadi solusi yang sangat efektif bagi arsitektur big data modern.
Jadi, ini bukan tentang mana yang lebih baik, melainkan tentang mana yang lebih sesuai dengan kebutuhan proyek Anda.
Perbandingan Apache Cassandra dan Hadoop
Agar Anda lebih mudah dalam membandingkan, kami telah merangkum poin-poin utama tentang Apache Cassandra dan Hadoop dalam tabel di bawah ini:
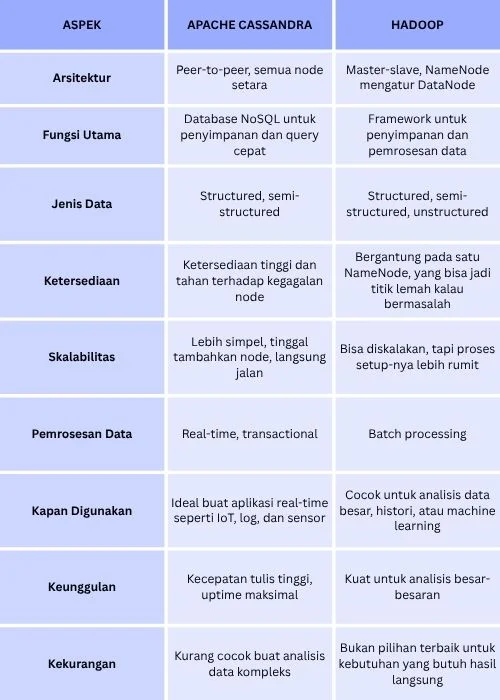
Dari analisis yang telah dilakukan, terlihat jelas bahwa Apache Cassandra dan Hadoop memiliki keunggulan masing-masing yang dapat disesuaikan dengan kebutuhan. Cassandra lebih unggul dalam kecepatan serta akses data secara real-time, sementara Hadoop efisien dalam memproses data dalam jumlah besar secara batch.
Kelebihan dan Kekurangan Apache Cassandra dan Hadoop
Sama seperti teknologi lainnya, Apache Cassandra dan Hadoop memiliki keunggulan serta kelemahan yang berbeda. Oleh karena itu, sangat penting bagi Anda untuk memahami aspek mana yang menjadi kekuatan dan apa saja yang harus dihindari:
Kelebihan Apache Cassandra
- Kekuatan Tahan Banting alias Fault-Tolerant: Jika satu node tidak berfungsi, sistem masih berjalan normal.
- Write Performance Sangat Cepat: Ideal untuk aplikasi yang terus menerus melakukan penulisan data, seperti log server atau perangkat sensor IoT.
- Mudah Diperluas: Menambah node baru? Tanpa kesulitan, Cassandra dapat secara otomatis mendistribusikan ulang data ke node baru, dan yang lebih menarik, sistem tetap hidup tanpa perlu dimatikan.
Kekurangan Apache Cassandra
- Query Terbatas: Cassandra tidak memiliki dukungan untuk JOIN dan subquery seperti yang ada di SQL.
- Kurang Efisien untuk Analisis Kompleks: Ini bukanlah pilihan ideal bagi ilmuwan data yang memerlukan pengolahan data dalam volume besar secara bersamaan.
Kelebihan Hadoop
- Sangat Ideal untuk Big Data Analytics: Dapat mengelola ratusan terabyte informasi? Hadoop sangat mampu.
- Hadoop memiliki tingkat fleksibilitas tinggi karena dapat mengolah berbagai jenis data, baik yang terstruktur maupun yang tidak teratur.
- Open-Source dan Komunitasnya Aktif: Banyak alat yang mendukung Hadoop, seperti Hive, Pig, dan Spark.
Kekurangan Hadoop
- Tidak Real-Time: Hadoop lebih unggul dalam pemrosesan batch. Jika Anda memerlukan hasil segera, tidak terlalu sesuai.
- Tergantung NameNode: Jika NameNode mengalami gangguan, sistem dapat terpengaruh.
Dengan mengetahui kelebihan dan kekurangan dari Apache Cassandra dan Hadoop, Anda dapat lebih cerdas dalam memilih teknologi yang paling sesuai untuk proyek atau kebutuhan bisnismu.
Pilih yang Sesuai Kebutuhanmu
Dari semua penjelasan yang telah disampaikan, satu hal yang bisa kita simpulkan, yakni memilih antara Apache Cassandra dan Hadoop tergantung pada kebutuhan spesifikmu, bukan mana yang lebih unggul. Jika Anda memerlukan sistem yang cepat, tangguh, dan dapat diandalkan untuk menyimpan data real-time dalam jumlah besar, Apache Cassandra mungkin adalah pilihan paling tepat.
Namun, jika Anda sedang mengembangkan sistem analitik yang memerlukan pengolahan data besar secara batch dan terstruktur, maka Hadoop adalah opsi yang sesuai.
Menariknya, banyak perusahaan modern saat ini mengintegrasikan kekuatan Apache Cassandra dan Hadoop dalam satu sistem. Cassandra digunakan untuk operasi sehari-hari, sementara Hadoop digunakan untuk analisis yang mendalam. Sangat fleksibel, bukan?
Agar kedua teknologi ini dapat berjalan dengan optimal, tentu kamu memerlukan infrastruktur yang solid dan stabil. Di sinilah VPS yang handal menjadi sangat penting. Ayo, mulailah membangun proyek big data kamu dengan performa terbaik di Cloud VPS Murah Hosteko! Dengan sumber daya yang didedikasikan, tingkat uptime yang tinggi, dan kontrol penuh, kamu bisa menjelajahi Apache Cassandra dan Hadoop tanpa batasan.